들어가며
데이터베이스는 결국 데이터를 저장해야 하고 데이터를 저장할 공간을 필요로 한다. 운영체제 위해서 동작하는 큐브리드는 운영체제로부터 필요한 만큼의 공간을 할당받고 이를 필요에 따라 효율적으로 사용한다. 이 글에서는 큐브리드가 영구저장장치에 데이터를 저장하기 위하여 내부적으로 어떻게 저장공간을 관리하는지에 대하여 이야기한다. 이를 통해 데이터베이스를 연구하고 개발하는 개발자들이 오픈소스 데이터베이스인 큐브리드에 좀 더 쉽게 접근할 수 있었으면 한다.
- 이 글의 내용은 버전 10.2.0-7094ba을 기준으로 하나, 최신 develop branch의 11.0.0-c83e33 에서도 차이가 없는 것으로 보인다.
큐브리드의 저장공간 관리
큐브리드 서버는 여러 모듈들이 복합적이고 정교하게 동작하며 데이터를 관리한다. 이 중 저장공간을 관리해주는 모듈로는 디스크 매니저 (Disk Manager)와 파일 매니저 (File Manager)가 존재한다. 이들의 역할을 명확히 하기 위해서는 먼저 큐브리드에서 저장 공간을 어떠한 단위로 관리하는지를 알아야 한다.
페이지와 섹터
페이지(Page)는 큐브리드의 가장 기본적인 저장공간의 단위이다. 페이지는 연속적인 바이트의 연속으로 기본 크기는 16KB이며, 사용자가 볼륨을 생성할 때 8K, 4K 등으로 설정 가능하다. 페이지는 IO의 기본 단위이기도 하다.
섹터(Sector)는 페이지의 묶음으로 64개의 연속적인 페이지로 구성된다. 공간을 관리할 때, 페이지만을 단위로 연산을 수행하는 것은 비용이 크므로 이보다 큰 단위인 섹터를 두고 사용한다.
파일과 볼륨
파일(File)은 특정 목적을 위해 예약된 섹터들의 묶음이다. 앞서 페이지나 섹터가 단순히 저장공간을 나누는 물리적인 단위였다면, 파일은 특정한 목적을 지니는 논리적인 단위이다. 예를 들어 사용자가 "CREATE TABLE .." 구문을 통해 테이블을 생성하면 테이블이 저장될 공간이 필요한데, 이 때에 파일의 일종인 힙 파일(Heap File)이 생성된다. 마찬가지로 인덱스를 생성하거나, 쿼리 결과를 저장하는 등 데이터를 저장할 일이 생긴다면 그 목적에 맞는 파일이 생성된다. 여기서 말하는 파일은 OS에서 open() 시스템콜을 통해 생성하는 OS 파일과는 구분된다. 이 후 이 글에서 특별히 언급하지 않는 한, 파일이라는 단어는 이 큐브리드의 파일을 의미한다.
볼륨(Volume)이란 큐브리드에서 데이터를 저장하기 위해 운영체제로 부터 할당받은 OS 파일이다. "cubrid createdb .."등의 유틸리티를 통해 생성한 데이터베이스 볼륨을 말한다.
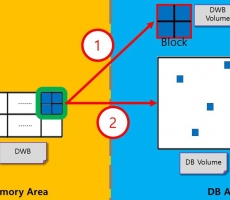
다음은 이들을 간략히 도식화한 것이다.
사용자가 데이터베이스 볼륨을 생성하면, 큐브리드 서버는 이 볼륨을 앞서 이야기한 섹터, 페이지 단위로 나누고 파일이라는 논리적인 단위로 묶어서 데이터를 저장하는데에 사용한다. 그림을 보면 OS의 파일로써 생성된 볼륨이 여러개의 섹터로 나뉘어져 있는 것을 볼 수 있고 목적에 따라 각 섹터들을 묶어 힙 파일, 인덱스 파일 등으로 사용하는 것을 볼 수 있다.
Note
- 여기서 볼륨은 로그볼륨등이 아닌 데이터가 저장되는 데이터 볼륨만을 이야기 한다.
- 볼륨, 페이지, 섹터는 물리적인 단위인데 반해 파일은 논리적인 단위로 하나의 파일이 계속 커질 경우 여러 볼륨에 걸쳐서 존재할 수도 있다.
디스크 매니저와 파일 매니저
디스크 매니저와 파일 매니저는 이러한 저장공간 단위들을 관리하는 모듈이다. 각각의 역할은 다음과 같다.
디스크 매니저 (Disk Manager): 볼륨 공간 전체를 관리한다. 파일 생성 시 섹터들을 예약(Reservation)해 주고, 섹터가 부족하면 OS로부터 섹터를 더 확보하는 등의 역할을 한다.
파일 매니저 (File Manager): 큐브리드 파일들의 저장 공간을 관리한다. 파일이 추가적인 공간을 필요로 할 때 예약한 섹터들 중 페이지를 할당(Allocation)해주고, 더 이상 할당할 페이지가 없다면 디스크 매니저로부터 추가적인 섹터를 예약하는 등의 역할을 한다.
다음은 이들의 관계를 도식화한 것이다.
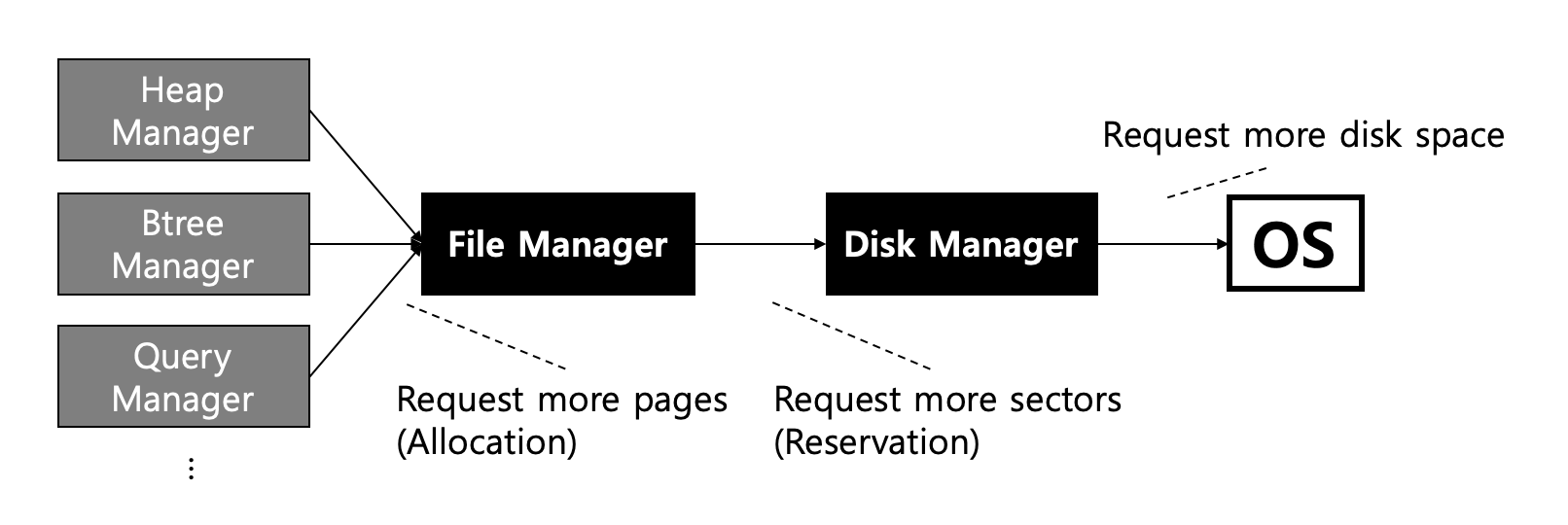
힙 매니저, 비트리 매니저 등 다른 모듈들이 데이터를 저장할 공간이 필요할 경우, 목적에 맞게 파일을 생성하고 필요한만큼 저장공간을 할당한다. 파일매니저가 파일을 위하여 공간을 확보할 때에는 항상 섹터단위로 확보한 후, 내부적으로는 페이지 단위로 할당한다. 파일이 예약한 섹터를 모두 소진하여 더이상 페이지를 할당할 수 없게 되면 디스크 매니저로부터 섹터를 예약한다. 볼륨내의 저장 공간이 모두 소진되었을 경우, 디스크매니저는 OS로부터 추가적인 공간을 요청한다.
아래에서 각 요청에 대한 처리가 어떻게 이루어지는지 자세히 살펴보자.
파일 사용 중 공간이 부족할 경우엔 어떻게 될까?
만약 파일 사용 중에 할당받은 공간을 모두 사용하면 어떻게 될까? 예를 들어 테이블의 레코드들이 저장되는 힙파일에 삽입연산이 발생했는데, 더 이상 공간이 없는 경우등을 말한다. 답은 "추가적인 페이지를 할당받는다."이다. 페이지 할당과정을 이해하기 위하여 먼저 파일의 구조를 살펴보자.
파일은 섹터단위로 디스크 매니저로부터 저장 공간을 확보하고, 이를 페이지 단위로 필요할 때마다 할당해서 사용한다. 이를 위해서 파일 매니저는 각 파일마다 파셜 섹터 테이블 (Partial Sector Table)과 풀 섹터 테이블 (Full Sector Table)을 두고 예약한 섹터의 할당 여부를 추적한다.
- 파셜 섹터 테이블 (Partial Sector Table): 예약한 섹터 중, 섹터의 64개의 페이지 중 1개의 페이지라도 미할당된 상태라면 이 테이블에 등록된다. 각 섹터는 다음의 정보를 지닌다: (VSID, FILE_ALLOC_BITMAP)
- 풀 섹터 테이블 (Full Sector Table): 예약한 섹터 중, 섹터 내의 모든 페이지가 할당되었을 경우에 이 테이블에 등록된다. 각 섹터는 다음의 정보를 지닌다: (VSID)
VSID는 섹터의 ID이고, FILE_ALLOC_BITMAP은 각 섹터 내 64개의 페이지의 할당 여부를 표시한 비트맵이다. 이 두 테이블은 기본적으로 파일 헤더 페이지에 저장되며, 파일이 커짐에 따라 추가적인 시스템 페이지를 할당받아 테이블을 저장하기도 한다.
페이지 할당 과정은 단순하다. 이렇게 두가지 테이블에 예약한 섹터 정보를 유지함으로써 (사실 이 두 테이블의 정보를 유지하는 것이 다소 복잡하다.), 추가적인 페이지가 필요할 경우 파셜 테이블의 엔트리를 하나 골라 비트맵의 비트를 하나 켜주는 것으로 페이지 할당을 완료할 수 있다. 만약 파셜 섹터테이블에 엔트리가 존재하지 않는다면 예약한 모든 섹터의 페이지를 할당해서 사용 중인 것이므로, 추가적인 섹터를 디스크 매니저로부터 예약해야 한다.
Note
- 페이지 할당은 System Operation (Top operation)으로 처리된다. 이는 트랜잭션중에 추가적인 공간이 필요하여 페이지를 할당하는 경우에, 트랜잭션의 commit, abort와 무관하게 페이지 할당 연산은 먼저 commit되는 것을 의미한다. 이를 통해 트랜잭션이 끝나기 전에 다른 트랜잭션도 할당된 페이지를 사용할 수 있게 되어(Cacading Rollback 혹은 기타 처리 없이) 동시성이 증가하게 된다.
- 파일 헤더에는 두개의 섹터테이블 말고도 유저 페이지 테이블 (User Page Table)이 존재한다. 이는 파일의 Numerable 속성을 위한 테이블로, 이 글의 범위는 넘어가므로 생략한다.
- 파일의 크기는 이론적으로 무한하게 커질 수 있으므로 섹터 테이블의 크기도 이를 추적할 수 있도록 계속해서 커질 수 있어야 한다. 이를 위해 큐브리드는 여러페이지로 이루어진 가변크기의 데이터 셋(set)을 저장하기 위한 File Extendible Data라는 자료구조를 가지고 있다.
파일 사용 중 더이상 할당할 페이지가 없다면 어떻게 될까?
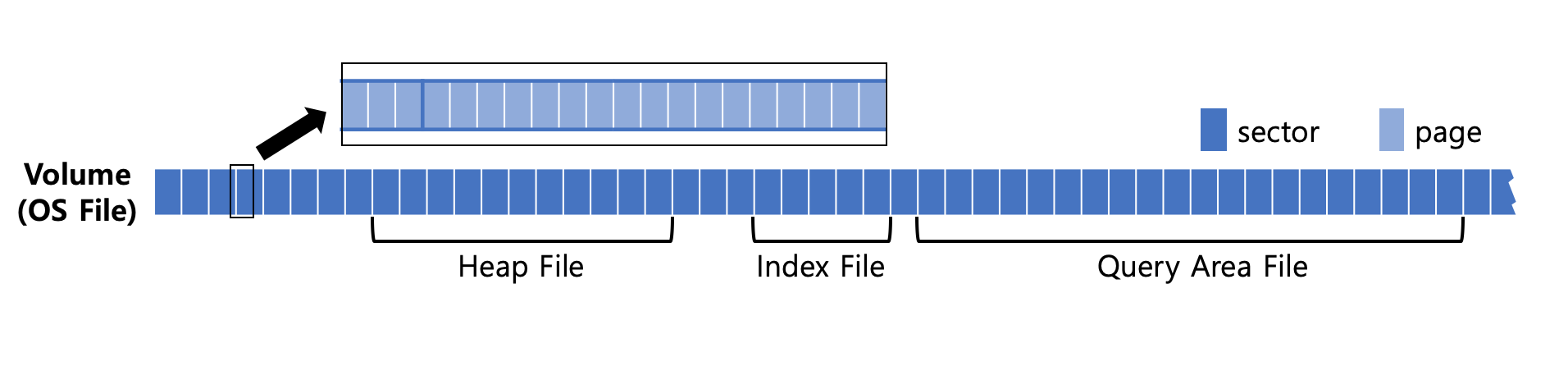
파일 사용 중 예약된 모든 섹터의 페이지를 사용했다면 추가적인 섹터를 예약해야 한다. 섹터의 예약이 어떻게 이루어지는지 살펴보기 전에 볼륨의 구조를 살펴보도록 하자. 다음은 볼륨의 구조를 도식화한 것이다.

볼륨의 볼륨 헤더와 섹터 테이블 (Sector Table)을 포함하는 시스템 페이지와 나머지 유저 페이지로 이루어져 있다. 섹터 테이블은 파일의 파셜 섹터 테이블과 유사하게, 볼륨내 섹터들의 예약여부를 비트맵으로 들고 있다.
페이지 할당 과정을 참고하면, 섹터의 예약 과정도 손쉽게 추측해 볼 수 있다. 섹터 테이블의 비트맵을 확인하고 예약되지 않은 섹터의 비트를 켜주는 것이다. 기본적으로는 이와 같으나, 섹터 예약은 여러 볼륨의 섹터 테이블들을 참고하여 예약 여부를 결정해야 하며, 그 과정에서 볼륨의 확장 및 추가 등의 작업이 일어날 수도 있기 때문에 효율성과 동시성의 증가를 위해 디스크 캐시 (DISK_CACHE)를 두고 다음과 같이 2 단계로 예약을 수행한다.
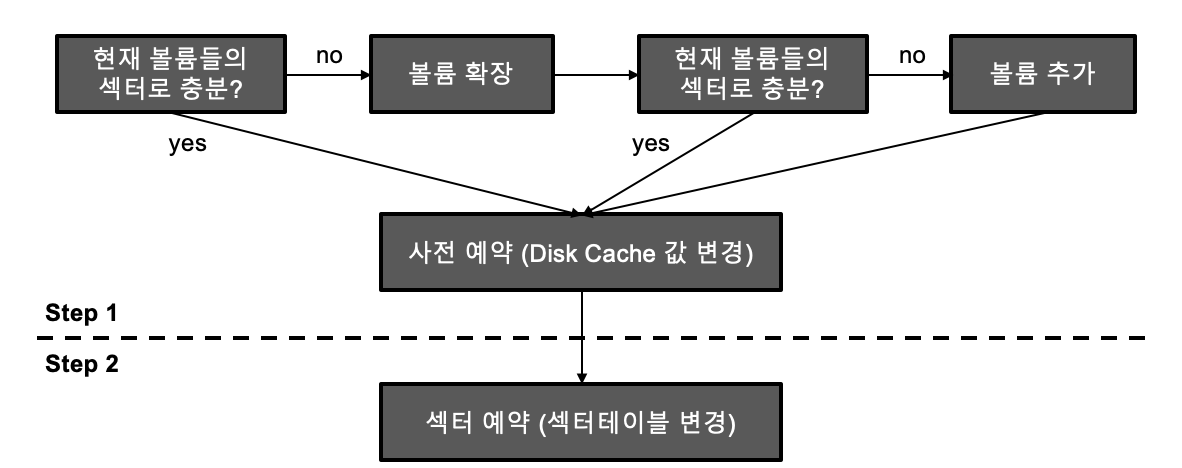
1. 디스크 캐시를 통해 섹터를 사전 예약한다.
2. 사전예약의 결정 사항을 바탕으로 실제 볼륨들의 섹터테이블들을 순회화면서 예약비트를 킨다.
그림과 같이 1의 과정에서 볼륨자체의 섹터를 모두 소진했을 경우에는 시스템 파라미터 (System Parameter)에 따라 볼륨을 확장하고, 최대 크기까지 확장하고나면 새로운 볼륨을 추가하기도 한다.
디스크 캐시는 전체 볼륨들의 섹터 예약정보들을 바탕으로 예약 시 필요한 값들을 미리 계산하여 가지고 있다. 예를 들어 각 전체 볼륨들의 가용 섹터 수 등을 섹터 테이블들의 정보를 바탕으로 가지고 있어, 이 값만 가지고 바로 현재 볼륨에서 예약이 가능할지 아니면 볼륨을 확장해야할지 등을 판단할 수 있다.
공간을 더 이상 사용하지 않는다면?
예약했던 섹터들, 할당했던 페이지들이 더 이상 필요하지 않다면 어떻게 될까? 물론 공간을 반환하여 다른 데이터들이 저장될 수 있도록 해야 한다. 반환 과정은 기본적으로 예약이나 할당 과정에서 섹터 테이블의 비트를 켰던 것과 반대로 비트를 끄고, 섹터 테이블들을 규칙에 맞게 재구성하는 것이다.
실제 공간을 반환하는 시점은 페이지 및 섹터를 사용하는 모듈의 정책에 따른다. 예를 들어 힙파일의 경우 데이터를 모두 삭제했다고 해서 바로 페이지를 반환하지 않는다. 힙 파일의 페이지를 반환하기 위해서는 해당 페이지에 있는 레코드를 모두 delete했을 때가 아니라, MVCC 및 Vacuum의 동작에 따라 더 이상 데이터가 필요없다고 힙 매니저가 판단했을 때이다. 또, 임시파일의 경우 정책에 따라 파일을 바로 제거하지 않고 다른 용도로 재활용하기 때문에 쿼리가 끝났다고 해서 쿼리 중에 사용한 임시 파일의 공간이 바로 반환되는 것은 아니다.
공간 반환은 postpone 연산 (Deferred Database Modification)으로 수행된다. 즉 트랜잭션 중에 공간을 반환하더라도 커밋 시점 전까지는 반환이 처리되지 않는다.
임시 목적 데이터
앞서 이야기한 내용은 영구 목적의 데이터들의 경우이다. 임시 목적의 데이터는 조금 다르게 처리된다. 여기에서는 이 차이점들에 대하여 간단히 정리한다. 그전에 먼저 데이터를 명확히 분류하고, 볼륨의 타입에 대해서 이야기해보자. 데이터는 크게 다음과 같이 두가지로 분류할 수 있다.
- 영구 목적 데이터: 영구 목적의 데이터는 영구적으로 보존되어야 하는 데이터로, 데이터베이스가 실행 중에 Failure가 발생하더라도 온전한 상태를 유지해야 한다. 예를 들어 테이블의 레코드를 저장하는 힙 파일, 인덱스를 저장하는 비트리 파일은 영구 목적 데이터를 저장하는 파일들이다.
- 임시 목적 데이터: 임시 목적 데이터는 쿼리수행에 따라 임시적으로 저장되는 데이터로, 데이터베이스가 재시작된다면 모두 의미없는 데이터가 된다. 예를 들어 쿼리 결과를 담는 중에 메모리가 부족하여 디스크에 쓰게 된 임시 파일이나, 외부 정렬 (External Sorting)과정에서 만들어진 임시 파일 등이 있다.
위의 이야기에서 알 수 있는 가장 큰 차이점은 데이터베이스가 종료되어도 데이터가 유지되어야 하느냐이다. 이는 ARIES를 따르는 큐브리드에서는 곧 리커버리를 위한 로깅이 필요성 유무를 이야기한다. 영구 파일의 경우는 영구 파일 내의 데이터가 변경될 때에 항상 로깅을 하고, 임시 파일의 경우는 로깅을 하지 않는다. 또한, 임시 목적의 데이터는 재시작시 유지되어야 할 필요가 없으므로 여러 파일 연산에서 동작이 훨씬 단순해진다.
임시 목적 데이터와 볼륨
데이터 볼륨의 타입에도 영구, 임시 두가지 타입이 존재한다. 데이터의 목적에 따라 어떤 볼륨에 어떤 데이터가 저장되는지를 도식화하면 다음과 같다.
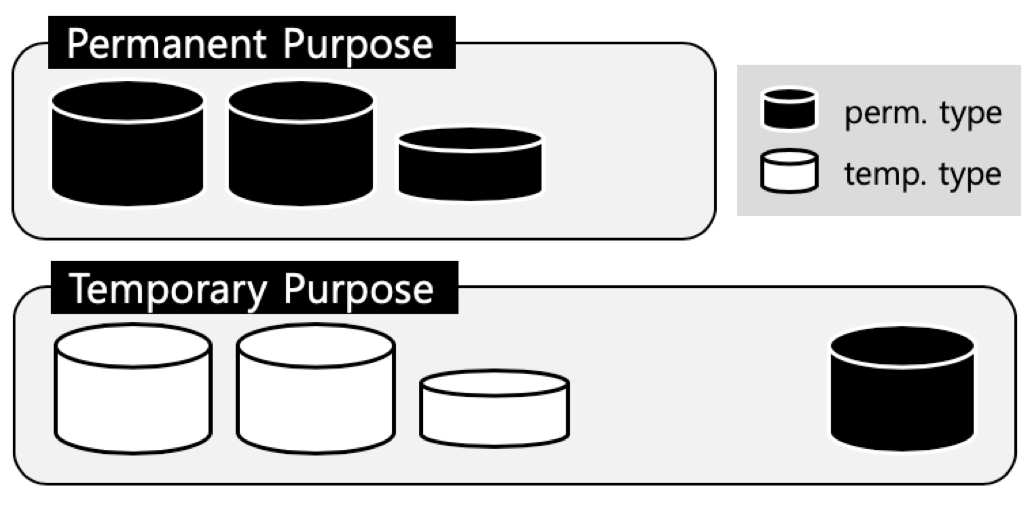
영구목적의 데이터의 경우에는 영구타입의 볼륨에만 저장된다. 반면에 임시 목적의 데이터는 임시타입, 영구타입 볼륨 모두에 저장될 수 있다. 이는 임시 데이터를 저장할 때마다 OS로부터 새로운 볼륨을 생성하고 포맷하는 것을 방지하기 위해, 사용자가 직접 임시 목적 데이터를 위한 볼륨을 추가할 수 있기 때문이다 (cubrid createdb -p temp). 임시 목적 데이터의 파일을 생성할 경우엔 사용자가 만들어둔 영구 타입의 임시 목적 볼륨을 먼저 찾아보고, 없을 경우에 임시 타입의 볼륨을 생성해 낸다. 임시 타입의 볼륨은 데이터 베이스 재시작 시 모두 제거되고, 임시 목적의 영구 타입 볼륨 역시 재시작 시에 내부의 모든 파일이 파괴된다.
임시 목적 데이터와 파일
임시 목적 데이터가 담기는 파일 (이하 임시파일)들은 영구 목적이 담기는 파일들에 비해 관리가 단순하다. 임시 파일은 주로 쿼리의 결과나 중간 결과 등 쿼리 수행 중에 많은 양의 데이터에 접근하게 될 경우에 이를 임시로 저장하기 위한 파일이다. 이는 어차피 제거될 파일들이기 때문에 관리를 위한 오버헤드를 줄일 수 있고, 영구 파일에 비해 짧은 주기로 자주 생성/제거되는 파일이기 때문에 연산 자체가 빨라야 하기 때문이다. 차이점은 다음과 같다.
- 로깅을 하지 않는다.
- 페이지를 반환하지 않는다.
- 파일을 다 사용하더라도 파괴하지 않고 재사용한다.
- 섹터테이블을 한 종류만 사용한다.
재시작되면 필요없는 데이터이기 때문에 로깅을 하지 않는 것은 기본이고, 페이지 내의 데이터가 더 이상 사용되지 않더라도 페이지를 따로 반환하지 않는다.
파일 또한 바로 파괴하지 않고 시스템 파라미터에 따라 일정 수만큼 임시 파일을 캐싱해두고, 이 후 임시 파일이 필요할 경우에 재사용하도록 한다. 캐시가 가득 찼을 때에만 임시 파일을 지우므로, 쿼리 수행 중에 임시 목적 데이터를 위해 사용된 디스크 공간은 쿼리가 끝나고 바로 반환되지 않고 유지되는 것을 확인할 수 있다.
영구 파일의 페이지 할당 과정에서 살펴본 섹터 테이블은 결국 페이지의 할당과 반환이 반복되는 상황에서 할당되지 않는 페이지를 빠르게 찾기 위한 것인데, 임시 파일의 경우에는 페이지 반환 자체를 하지 않기 때문에 단순히 파셜 섹터 테이블과 같은 형태의 테이블 하나만을 사용하며 순차적으로 페이지를 할당해 나간다. 만약 섹터 내의 페이지를 모두 할당했더라도 이를 풀 섹터 테이블로 옮기지 않는다. 단순히 예약한 섹터와 섹터들 내에서 어떤 페이지까지 예약했는지를 트래킹하는 용도로 사용된다.
이외의 기본적인 사항은 위에서 살펴본 디스크 매니저와 파일 매니저의 동작을 그대로 따른다.
참고자료
1. CUBRID Manual - https://www.cubrid.org/manual/en/10.2/
2. CUBRID Source Code - https://github.com/CUBRID/cubrid
3. Mohan, Chandrasekaran, et al. "ARIES: a transaction recovery method supporting fine-granularity locking and partial rollbacks using write-ahead logging." ACM Transactions on Database Systems (TODS) 17.1 (1992): 94-162.
4. Liskov, Barbara, and Robert Scheifler. "Guardians and actions: Linguistic support for robust, distributed programs." ACM Transactions on Programming Languages and Systems (TOPLAS) 5.3 (1983): 381-404.
5. Silberschatz, Abraham, Henry F. Korth, and Shashank Sudarshan. Database system concepts. Vol. 5. New York: McGraw-Hill, 1997.